
When we engage with new clients that are considering rolling out Salesforce for their users, we field tons of questions related to data. It’s one of the top concerns of users and executives alike – and it should be! It’s one of the most important aspects of planning for your implementation. When your users and management teams can rely on the quality and accuracy of data in Salesforce, it gives them the confidence they need to adopt the platform and see its value as an engagement and collaboration platform. Good data drives good business processes.
But data migration is just the tip of the iceberg when it comes to creating a sound Data Governance Strategy. At the outset of planning for your project, it’s important to consider many other factors that impact your long-term oversight and management. In this post, we’ll cover three foundational concepts that are important to define when you’re starting to build your strategy:
Data Definition & Migration
The first place to start with your Data Governance Strategy is defining which elements of data are most critical to the application that you’re building on the platform – and who’s in charge of making sure they’re reliable and accurate. Commonly referred to as a Data Dictionary, the definition of these elements will help you with all of your future planning steps because it provides a reference point for how you will migrate, manage, and enrich that data over the long haul. A good Data Dictionary should include the important data objects (like Accounts, Contacts, Opportunities), the attributes and fields that are important to track for each object, and a working definition about how that attribute will be used in your organization. In some cases, it may be advisable to even include the field types or relevant values. If you’re not sure where to start and want to see the Data Dictionary for standard Salesforce objects, you can start with this comprehensive API Guide which allows you to drill down into each object and see Salesforce’s native definition for objects and fields.
After you’ve defined which sets of data are important to you and the application you’re trying to build, it’s important to determine which sources of data you will want to migrate into the application. Which databases or legacy applications capture and control the type of data in your dictionary? It’s helpful to include a section in your Data Dictionary on where each data element originates, which will be the ongoing system of record for that data, and who is in charge of maintaining that piece of data in the long term.
Finally, after you’ve defined your Data Dictionary and the Data Sources from which you will migrate, there are a number of migration-related questions you should think about when planning your critical migration path. What should you do with all your historic data? Should you bring over all years of data, or just a subset that’s most recent and relevant to your customers and prospects? Which foreign keys or external IDs should you include to help you with future updates or integrations? Are there data elements in your historic data that aren’t very useful in Salesforce and will just cause confusion and noise? You should definitely consider leaving those items behind and start fresh with a clean slate.
Data Standards, Validation, and Automation
Even before you do your migration from the sources you’ve identified in the first step, it’s critical to define all the standards and system validations you want to enforce to ensure that once migrated, your data stays consistent and accurate to support process efficiency and reliable reporting. In this part of your plan, it’s helpful to take a look at your Data Dictionary through a different lens and identify answers to the following questions for each object:
- What format do I want to use as a naming convention for each object/record?
- For each object, which fields should be required at each stage in their related processes?
- Which fields have a known set of valid responses? (e.g. state names, address fields, field dependencies)
- Which fields should I control with logical validation to prevent user error at the point of entry? (example: entering a Close Date in the past for an open Opportunity)
- Which fields will be critical in support of reporting so we ensure they’re always filled out?
The reason it’s important to consider and define the answers to these questions is because this will help you build your plan to properly configure required fields, validation rules, dependent picklists, process builder workflow updates, and other automation necessary to achieve your adoption objectives. The ultimate goal of this step is to define what complete and accurate data looks like so that you can identify what mechanisms you can build to help take the guesswork out of day-to-day data entry for your users and promote confidence in your carefully considered application. For example, one situation we often encounter is when users are supposed to manually update the Status of an Account. If that’s a critical element in your data (it is!), why not set a standard and supporting workflow that automatically updates the Status when an Opportunity is Closed Won? That way, your reporting can be bulletproof and not rely on users remembering this critical element.
And don’t forget! As you build new features and functionality into your apps, you should revisit these standards to identify new ways to continue simplifying data entry and enhance usability!
Duplicate Prevention and Resolution
Now that you’ve defined your data standards and identified how you’ll validate and automate to ensure they’re enforced, it’s time to think about preventing duplicates and dirty data. No one wants dirty data! There are a few key considerations you’ll want to make in planning for duplicate prevention, including:
- Which records are most likely to attract duplicates? (e.g. Leads, Accounts, Contacts)
- Which tools will you use to prevent and address duplicates?
- What prevention mechanisms do you want to be immediate, when a user tries to create or update a record?
- What prevention mechanisms do you want to be batched on a regular cadence of ‘data sweeps’?
- What data sources might throw a monkeywrench into your best-laid plans and might warrant their own resolution plan? (e.g. marketing campaign imports, public web forms)
First up, Salesforce provides some great native tools to help you with duplicate prevention in real-time – both on Salesforce Classic and within the Lightning Experience. If you’re not familiar with these tools, you should definitely check them out here.
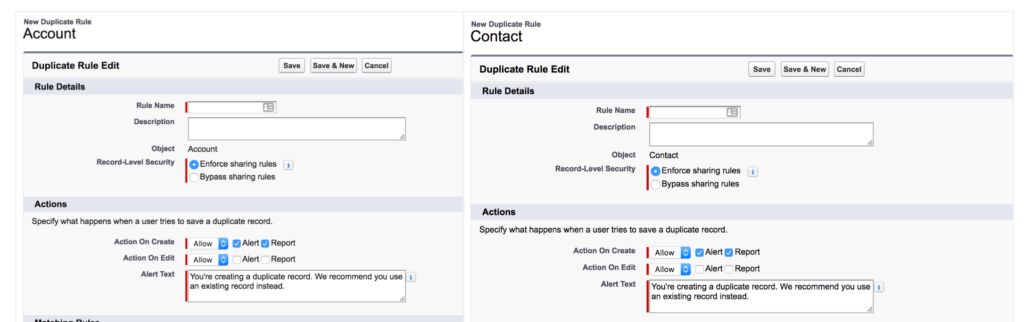
Secondly, if you’re looking for batched data sweeps on a regular cadence, we’re big fans of the CRMFusion app called DemandTools. It’s an indispensable tool for administrators looking to monitor their data quality, identify and resolve duplicates, and even save data scenarios so they can schedule regular sweeps of data to keep it fresh and clean. In addition, their DupeBlocker tool also provides added complexity and workflow routing to the native Salesforce duplicate prevention toolset, so if you want to route potential duplicates behind the scenes to power users or data administrators without interrupting your user workflow, they’ve got you covered.
Reached Data Overload?
Hopefully, this post gives you a good idea of where to get started with your Data Governance Strategy. In a future post, we’ll cover additional governance principles like Data Enrichment, Data Backup, and how to tell when you need a Master Data Management component to your plan. Be sure to subscribe to the blog to get the heads up when we’ve launched those topics!
Have questions as you’re building out your plan? Feel free to post them here in the comments or hit us up on Twitter at @silverlinecrm!


