
Reading Time: 5 minutes
This is the first in a multi-part series talking about continuous delivery on Salesforce. This post will be focused on setting up a Continuous Integration process for the code portions (classes, triggers, components, pages, static resources) of the metadata and future posts will cover configuration, data, and bundling these together for seamless deploys.
Large deployments, particularly in “living” environments where multiple team members may be making metadata changes, often end up as weekend work, or worse, all-nighters.
First off, what is Continuous Delivery and why is it a Good Thingtm?
From Martin Fowler:
- Your software is deployable throughout its lifecycle
- Your team prioritizes keeping the software deployable over working on new features
- Anybody can get fast, automated feedback on the production readiness of their systems any time somebody makes a change to them
- You can perform push-button deployments of any version of the software to any environment on demand
The key test is that a business sponsor could request that the current development version of the software can be deployed into production at a moment’s notice – and nobody would bat an eyelid, let alone panic.
Continuous Integration is an important tool for Continuous Delivery – constant branch merging and automated unit testing makes for healthier code, and is critical for the ability to push out working code at a moment’s notice.
In Salesforce terms that means
- Code in the master branch of your git repository should be deployable to production at all times (75% test coverage, triggers covered, etc.)
- You should be able to deploy code from your source control system to production via an automated build process
At Silverline, we’ve set up our CI (Continuous Integration) process using the following:
- Jenkins
- The force.com Migration tool
- Bitbucket (though any Git repo accessible from your Jenkins server will do)
- JIRA (for reporting and task delegation)
High-Level flow
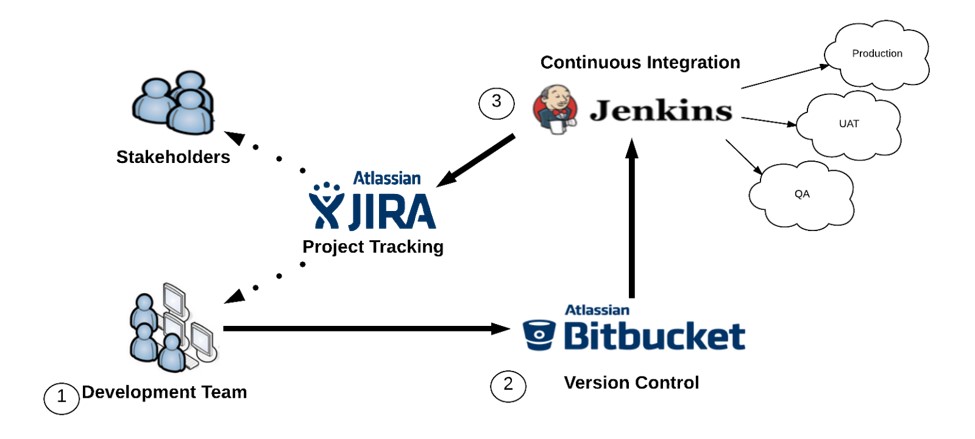
The Development Team
As a best practice, the development team should all be working on their own separate dev sandboxes. This prevents people from stepping on each others toes and forces everyone to commit any necessary dependencies to git. Using CI to push each member of the development team’s changes to a consolidated development sandbox where QA and initial testing can take place, this adds to the process a necessary first evaluation of development being “done” and helps to guarantee that what’s in the git repo is the source of truth, not what is in any particular Salesforce environment, which are not version controlled (a major pain point for careless Salesforce developers). It also ensures that each member of your development team is made explicitly aware, at the time they commit, what the configuration dependencies they’ve created are, or what environmental changes others have made will cause potential problems for their work, and need to be considered downstream. Similar to the fail-fast principle in a runtime environment, it is best for these failures to happen as early in the process as possible, so that the root cause is easy to track down, document, and fix.
Bitbucket (Version Control)
We follow a feature branch model in Git where a developer creates a separate branch for every item they are working on. In addition, we have a branch for every SF org that we will be deploying to (master, uat-master, prod-master, etc.). Deploys are kicked off by merging into these branches.
A developer would work in their own dev sandbox and feature branch. Once the developer is ready they would merge their feature branch into master which would run the apex tests and deploy the code to an internal QA org. Once the code passes QA it would be merged into a UAT branch which would deploy it to a full sandbox for end-user testing. Thus, for code, at least, the source of truth always exists in the repo, rather than in individual environments, and development is never hindered because Bob wanted to refresh the sandbox / run a destructive batch / load a million rows of test data while Alice was trying to get work done.
After passing end-user testing it would be merged into a production branch which would deploy it to production.
Jenkins
Since we manage a lot of different orgs we built a custom Jenkins plugin to make it easier to create the build.xml file and set the force.com migration tool parameters.
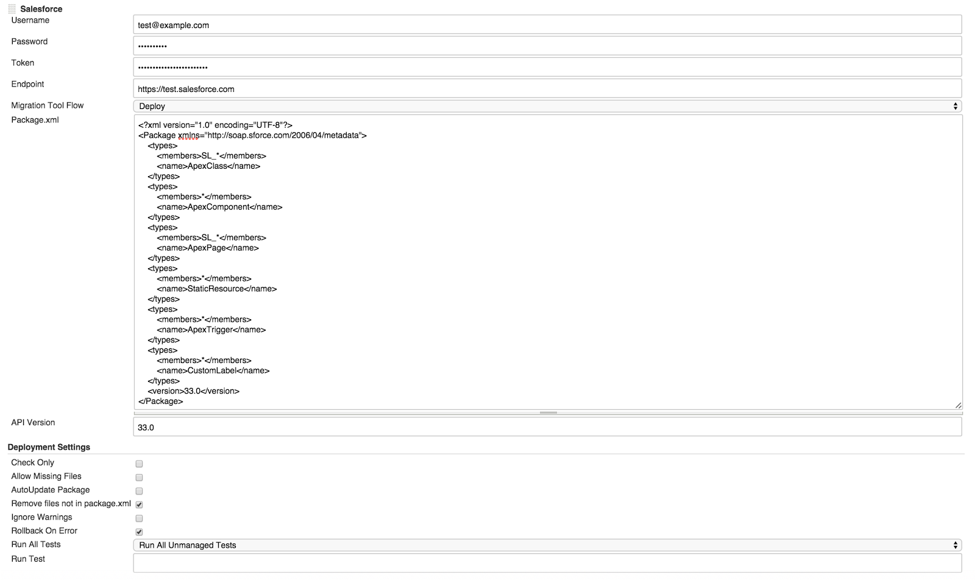
Our build is automated using webhooks, ant, and the force.com migration tool. When code is committed to certain branches of the repo, a webhook is sent to Jenkins which runs the build with the specified configuration, deploying that branch to a specific org. Ideally, all deployments are handled this way, but we’ll talk about deploying all metadata, including configuration as well as code, in a later post.
Jenkins is also used for all Asset/Solution deployments. In order to deploy the most recent version of a solution to a customer org we just type in the org credentials in Jenkins and run the build. This pulls the newest version directly from the repository and deploys it to the org. No need for constant packaging and repackaging of assets when features/fixes are added.
Deployment Pipeline

At any time, it should be possible to merge one of the working branches into production and successfully deploy it.
Feature Branch. Features branches are where active development happens. When an individual developer or set of developers working on a feature branch is satisfied the feature is complete and in a working state, they’ll merge their feature branch into Master.
Master. Master is trunk. This is the work in QA or work that has passed QA. It is synonymous with the code in the QA/consolidated dev org.
UAT-Master. UAT-Master is for, as the name suggests, UAT. In an ideal world, merging this branch into Prod-Master (see below) would result in no angry calls. Work here has passed internal development QA and may have passed end user testing. It is synonymous with the code in the UAT org.
Prod-Master. Prod-Master is, the source of truth for all production code. Merging to this branch kicks off the deploy to production – and what was once an excruciating process is that much less agonizing. Prod-master is only ever touched by merges from UAT-master, and thus each commit to Prod-Master represents a jenkins build as well as a capital-R “Release”.
Of course, the complex reality of software development is that often a feature is production “ready” from a development standpoint, but some other part of the process is holding up the actual deployment of the feature to the production environment. You might ask, “if a merge into a branch kicks off a build, how do I deploy only a subset of the functionality in that build”? The answer is the package.xml file, which in our case, is generated dynamically by our jenkins plugin, configurable in the jenkins job itself. This will necessarily violate the symmetry of repo and org – some features or feature versions may exist in your repo that have not been deployed to a given org, but it can definitely save time when you must absolutely deploy only a subset of features for internal development QA or UAT, or even to the production environment.
The benefits of utilizing Continuous Integration as part of a Continuous Delivery strategy are numerous. It reduces snap deployment time for hotfixes or feature requests, enforces compile-time checks for git repo health, ensuring the source of truth is under full, proper version control, and is a tremendous time saver overall.
Subscribe to the blog so you don’t miss part two of this post!


